How it is going AI vibe coding
When I started experimenting with AI vibe coding, I wouldn't have predicted that it would actually be useful. While I am still unsure about trusting whatever is returned by Claude for professional code, it has earned its spot for personal projects.
In the last couple of months, I have been able to knock off several items on my running tally of software projects. Most of the items are silly but are still worth it because the math has changed on how good they need to be. When the investment to write them goes down significantly (as with AI vibe coding), then building them trends towards zero.
Knocked off my list are 3 iOS apps, 2 native macOS apps, 2 web apps, and a Chrome extension.
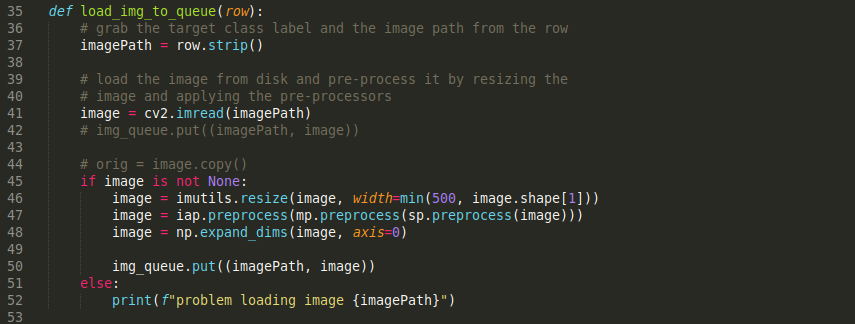
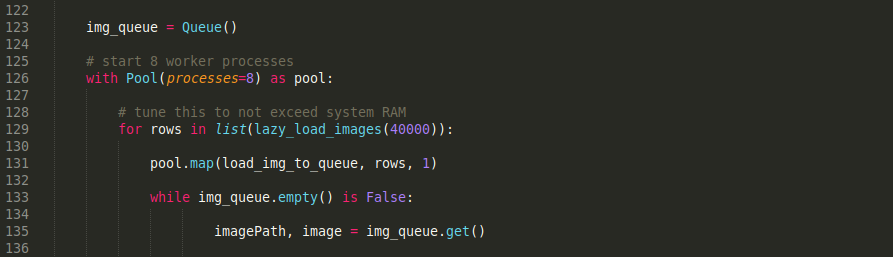
iOS apps are something I have never put in enough effort to really learn. Every couple of years, I dabble at trying to make something trivial, but the amount of effort is always too high for the expected return. One great benefit to coding in Swift is that it is a compiled language, so I can instruct my AI coding assistant to keep chasing compiler errors and get back to me when it builds cleanly. This has made it a breeze to build with.
So far, I've built for iOS:
- A personal CRM to get better at remembering to talk with friends. Turns out there is no practical way to access call records or messages, so this died quickly. The fast iteration cycle let me try several alternative methods, but ultimately, it didn't work.
- A viewer for construction equipment for my toddler. Who doesn't love big trucks?
- An uncertainty calculator for exploring different outcomes when you don't have all the numbers to calculate. This may actually be released to the App Store.
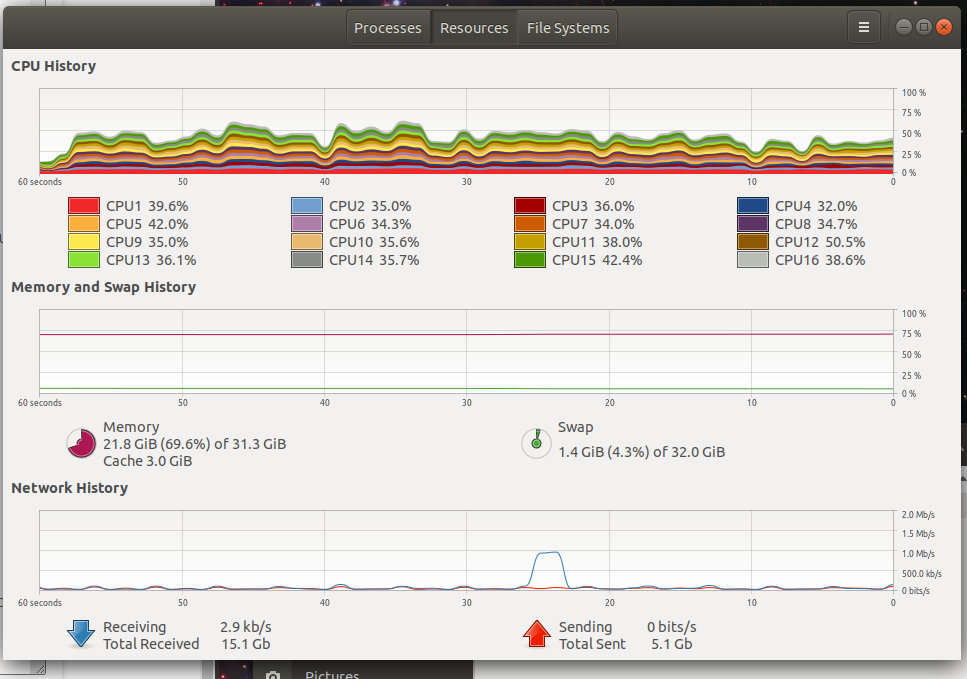
For macOS, I have always just written Python. Trying to use more of the considerable system resources is always a challenge and usually not worth dealing with. I wanted to make use of all the cores/GPUs on my M4 Pro.
- A file system watcher to make sure my git repos are in sync. One thing I hate is having dangling changes or unchecked-in files on a local machine. Having a menu bar icon and a native way to watch FSevents is the best solution here. This probably won't get released, but it is incredibly helpful to run myself.
- A Tableau alternative for EDA (exploratory data analysis). This was much harder than I thought and falls into the deceptive category of problems that are easy to get started with but exponentially harder when dealing with real data. The goal was to make a tool to help make sense of a single project and instead got pulled into solving an even harder problem in a generic way. This got abandoned because it wasn't viable. I might have to try again if I get a better idea.
Web apps are my bread and butter. I don't need technical help writing them, but it is nice to have an AI assistant generate all the boilerplate when setting up a project.
- A web app to aggregate the screenshots folder across multiple machines. It runs on my Synology NAS, so it has access to all my data and is also available to all machines. I have a decade of screenshots and screen recordings that are nice to refer back to. It is a nicer way to access older demos without doing the YouTube dance.
- Personal bookmark keeper with a content recommender. This started so I could explore how to build a recommender. Using examples datasets from Kaggle is a struggle because I don’t have a sense for the quality of recommendations. The explore vs exploit tradeoff is easier to see when I understand the domain better. It has now expanded to pull in my RSS feeds. This will probably be released at some point because it is great to have. It only makes sense to be as self-hosted because I don't trust companies to manage my data responsibly.
The Chrome extension to remove shorts was written about here. . I don’t think it has enough appeal to deal with the Google review process. Extensions can access a ton of data and I don’t really want to have that liability.
In conclusion, at $20/month, it makes sense to have an AI assistant write a lot of these projects. For the low risk of errors in them, vibe coding is acceptable for making something good enough.